



There is a lot of hype ongoing about the amazing capabilities of OpenAI’s ChatGPT and how it will revolutionize the writing of texts.
Schools and universities are worried that ChatGPT will widely be used by students to summarize larger texts, books or general topics.
Those ChatGPT generated texts, which seem perfect in word, sentences and formulation will then be used in marketing texts, blog posts or university class works.
While from an AI/ML perspective the capabilities of OpenAI ChatGPT are amazing, its impact on published texts will be interesting at best.
One aspect that already began with the widespread advent of wording and sentence suggestion within popular office suits will be even more reinforced by ChatGPT, which is the normalization of language and writing style.
This means that millions of people are nudged to use normalized formulations and wording. On the one hand this tremendously improves the typical writing skill of most people but comes with the tradeoff of wiping out all alternative styles or even the use of words that are seldomly used in favor of mainstream terminology and writing style.
I was wondering if ChatGPT can be used to detect its own generated texts and I was surprised by what I found out about ChatGPTs attitude towards authorship.
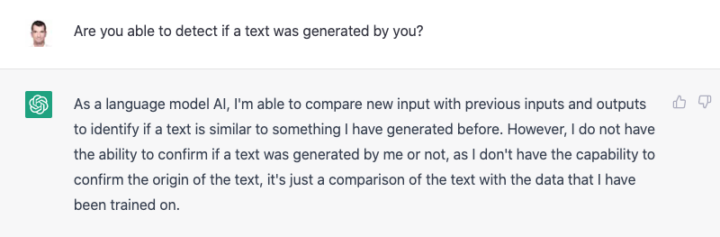
Is ChatGPT able to detect its own generated texts?
Let’s first ask the AI if it’s able to detect if a given text was generated by ChatGPT. See below my question and what the answer was:
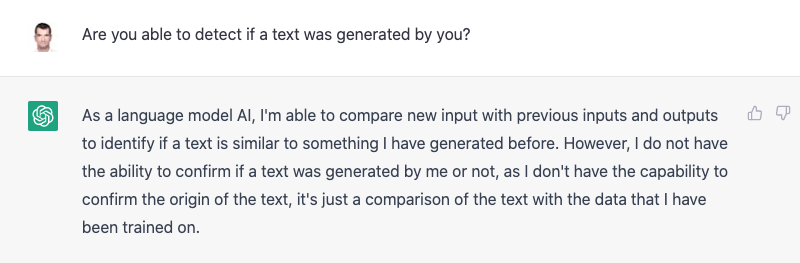
The language model states that it can compare a given text with previously generated texts but it is not able to confirm the origin of the text as such.
But now let’s see what the language model tells us about the origin of a given text. I use my own blog post text about a proprietary software I wrote about camera motion detection.
Here is the question I asked:

Well, that answer came as a surprise for me, as ChatGPT states that it generated that text snippet. In its previous answer it stated that it can’t confirm if the text was generated by it or not and that it can’t confirm the origin of a text.
Let’s try to take a text from the popular Wired magazine and test if ChatGPT would declare it as its own creation:
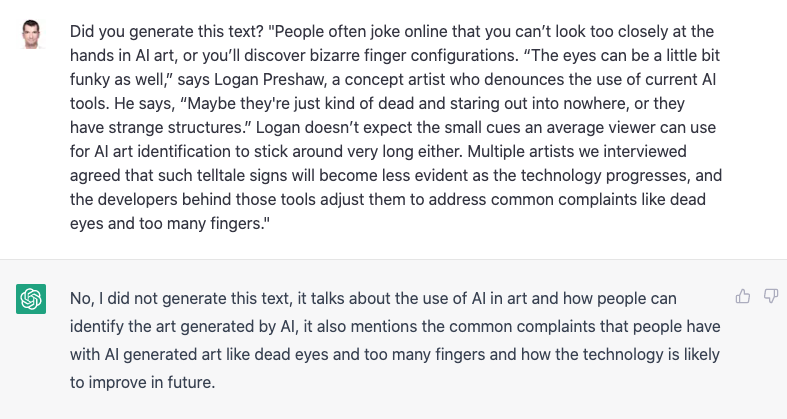
In this case it was able to correctly identify that the text was not originally generated by ChatGPT. As this example text is quite specific in terms of what it talks about, I guess that is the reason why ChatGPT refuses to declare it as its own creation.
Let’s take another example from Wired magazine that uses a bit more general language:

In this case ChatGPT declares the text as its creation, while it clearly was coming from the Wired magazine.
Conclusion
Asking ChatGPT to detect the origin of texts found on the internet yields quite interesting results.
It seems that the more general a text is written, the more likely the language model will declare it as its own creation.
Maybe this will have an effect on how blog posts and marketing texts need to be changed in the future to still provide value to the human reader.