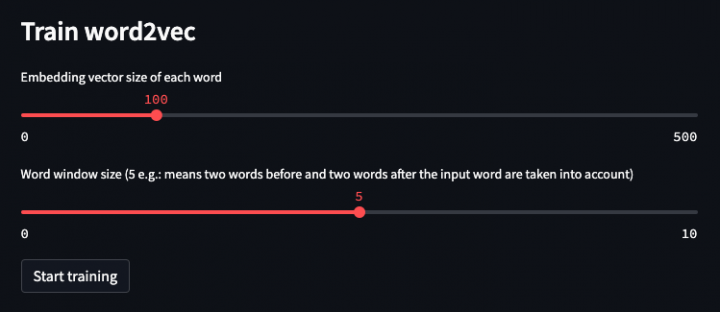
Within the last weeks, I thought about building a service for automatically answering incoming user questions by using a repository of previously answered questions. The benefit of such an automatic answering system is obvious, but as a foundation for that implementation, a trained text association model is needed. A large corpus of existing texts therefore […]
Web Text Scraping and AI Model Training with Streamlit